

NPLG 1.5.23: The Importance of Trustworthy Data
The best PLG founders, startups, strategies, metrics and community. Every week.

Current subscribers: 5,333, +290 since last week (+5.8%)
Share the PLG love: please forward to colleagues and friends! 🙏
Guest Blog Post, Ben Williams

For this edition of Notorious PLG, we are fortunate to have PLG leader Ben Williams share with our community his practical guidance and advice. Ben was most recently a VP of Products (Developer Journeys, PLG) at Snyk. If you aren’t familiar with Snyk, it is one of the most successful developer-focused PLG startups and just closed a financing round at ~$7.4B valuation (more info in the financing update section).
Ben has been all in on PLG for several years and has recently launched his own PLG advisory and consulting firm, The Product-Led Geek. Ben has deep experience and thinking not only in growth strategies, tactics and frameworks but also about how to build culture and teams that are setup for PLG success. We hope you enjoy this week’s edition of Notorious PLG:
The Importance of Trustworthy Data
“Product-led growth (PLG) allows companies to leverage the power of their product to create business momentum across three key growth levers of acquisition, retention and monetisation.
For companies adopting a PLG go-to-market motion, every function in the business from product management, design and engineering to sales to customer success to support and beyond rely on product usage data to plan, prioritise, and make effective user, team and customer centric decisions. Self-service analysis and high levels of data literacy are the norm. But to be both effective and efficient, it is crucial that decisions are informed by reliable, trustworthy data. Without trustworthy data, you risk making decisions that waste resources and have potentially much more negative impact through missed growth opportunities.
What makes data trustworthy?
So what do I mean by trustworthy data? For data to be trustworthy, it needs to be accurate, reliable, up to date, consistent, continuous, complete, and attributed to (and representative of) the cohort, population or problem being studied. For the purpose of this blog, I'm really focusing on behavioural event based data created from product usage. If this data has any hygiene issues that create even the slightest whiff of inaccuracy, then trust issues start to arise, meaning people will be hesitant to make decisions based on it.
It's difficult, costly, and in many cases impossible, to retrospectively change event based data - and that assumes you know there's a specific issue in the first place. The longer that issues with the quality of your data persist, the greater the impact, and so it becomes critical to consider how to prevent such issues from very early on.
In the worst cases I've seen several months worth of collected data be effectively invalidated and rendered useless for decision making. Imagine the activation metric you've been investing in driving improvements to be invalidated because you discover that the model used to derive the metric was based on assumptions made on flawed data. Or worse, you don't discover the issue and after months of effort are left scratching your head as to why the improvements you've made haven't had the broader growth impact you anticipated.This is the stuff of nightmares for any product and growth professional.

Impact beyond bad decisions
And beyond analytics platforms, in PLG companies product usage data is being piped to and used as an input signal to many business critical systems (product-led sales platforms, lead scoring systems, marketing automation tools, CS platforms, support tooling and so on) so any potential problem with data at source can proliferate to create widespread impact. For those adopting a product-led sales process, data issues can mean reps are spending disproportionate time on the opportunities that are unlikely to close (or would close without touch) at the expense of those where their involvement will be most likely to help close. And the impact isn't just internal; with PLG all customer communication is an extension of the product experience. Bad data driving automated messaging can quickly cause your users and customers to lose trust in your brand.
Data governance for PLG companies
PLG companies should be investing in data governance from day one. Pretty much everything I’m writing about here is equally applicable to non-PLG companies, but for those with a PLG GTM model, data is the lifeblood of your business, and this isn't something you can afford to overlook or postpone. For the companies that I advise this is often a topic of early conversation when we start to look at product data. Fortunately some very lightweight policies, practices and standards can serve the need without slowing down dev teams or the pace of innovation. Here are 3 important things to focus on:
Develop a simple instrumentation style guide, and ensure that frontend and backend events are clearly disambiguated.
This will make a big difference in consistency and consumability of the data which ultimately provides greater levels of trust.Ensure that your data schema design is collaborative.
This best practice can really help increase the level of trust in your product data, and ensure that it has wide utility. Product teams should work with key stakeholders across the business to collaborate on tracking plans with the aim of making sure that the data will be able to answer questions important to all parts of the business, avoiding otherwise often necessary rework, and empowering teams to be able to leverage the data most effectively, based on a common understanding and shared language.Create a single source of truth for tracking data.
Starting with something like a shared event tracking dictionary in a spreadsheet or Airtable base is common, but in my experience these can quickly become unwieldy, and are too disconnected from the actual event instrumentation within the product. Products like Amplitude Data (formerly Iteratively) and Avo provide a single source of truth for tracking plans and include features facilitating collaborative schema design and review. They are also deeply integrated into development workflows, meaning that the instrumentation implementation can be tested in your CI (Continuous Integration) pipelines for conformance to the designed schema and chosen style guide giving a significant boost to the confidence and trust in the data you're collecting.
A note on culture; It's a significantly easier path to trustworthy data when developers are also avid consumers of the data. Healthy high performing product teams are close to users and the impact of the work they are doing, quantitative curiosity is encouraged, features and experiments are built and shipped with questions, hypotheses and metrics considered up front, and developers are as much a part of the conversation about data (and decisions informed by data) as anyone else in the team. Fostering that culture means it becomes a no-brainer for developers to invest in collaborative taxonomy definitions, high quality instrumentation, and integration into their code processes and pipelines. I've seen both sides of the coin, and only one is fun.
Trustworthy data is essential for driving product-led growth. By creating reliable and representative feeds of product behavioural events, and implementing strong (not implying heavy) data governance practices from early on, companies can make informed, data-driven decisions and realise long-term benefits for their efficiency, growth and success.”
I would love feedback. Please hit me up on twitter @zacharydewitt or email me at zach@wing.vc. If you were forwarded this email and are interested in getting a weekly update on the best PLG companies, please join our growing community by subscribing:
Thanks for reading Notorious PLG! Subscribe for free to receive new posts and support my work.
PLG Tweet(s) of the Week:
Recent PLG Financings (Private Companies):
Seed:
Bonfire, a developer of a custom web3-native home platform intended to turn audiences into communities powered by their social token and NFTs, has raised $6.2M. The round was funded by Coinbase Ventures, Collab+Currency, Pear, Variant Fund, Palm Tree Crew Investments, Libertus Capital, Not Boring, Seed Club and New Enterprise Associates.
ClearVector, an identity-driven security system designed to help organizations protect themselves in a cloud-native and cloud-first future, has raised $3.1M. The round was led by Menlo Ventures.
Gynger, a sales acceleration platform intended to close deals by adding capital to stack, has raised $21.7M in debt and equity. The round led by Upper90 and Vine Ventures, with participation from Gradient Ventures, m]x[v Capital, Quiet Capital and Deciens Capital.
Pack, a San Diego–based company that does most of the coding for merchants and delivers it via a front-end headless commerce platform for Shopify merchants so they can create a more seamless customer experience, has raised $3M. Norwest Venture Partners led the round, with participation from Alpaca and Vanterra Ventures.
Series A:
Ngrok, a service that helps developers share sites and apps running on their local machines or servers, has raised $50M. The round was led by Lightspeed Venture Partners, with participation from Coatue.
Series F:
Dataiku, a centralized data platform designed to help businesses in their data journey from analytics at scale to enterprise AI, has raised $204M at a $3.7B valuation. The round was led by Wellington Management, with participation from Snowflake Ventures, Insight Partners, Eurazeo, CapitalG, ICONIQ Growth, Tiger Global Management, FirstMark Capital, Battery Ventures, Dawn Capital and Lightrock.
Series G:
Snyk, a Boston-based developer security company, has raised $196.5M at a $7.2B pre-money valuation. The round was led by Qatar Investment Authority, with participation from Tiger Global, Evolution Equity Partners, G Squared, Irving Investors, Boldstart Ventures and Sands Capital.
Recent PLG Performance (Public Companies):
Financial data as of last market close.
Best-in-Class PLG Benchmarking:

15 Highest PLG EV / NTM Multiples:
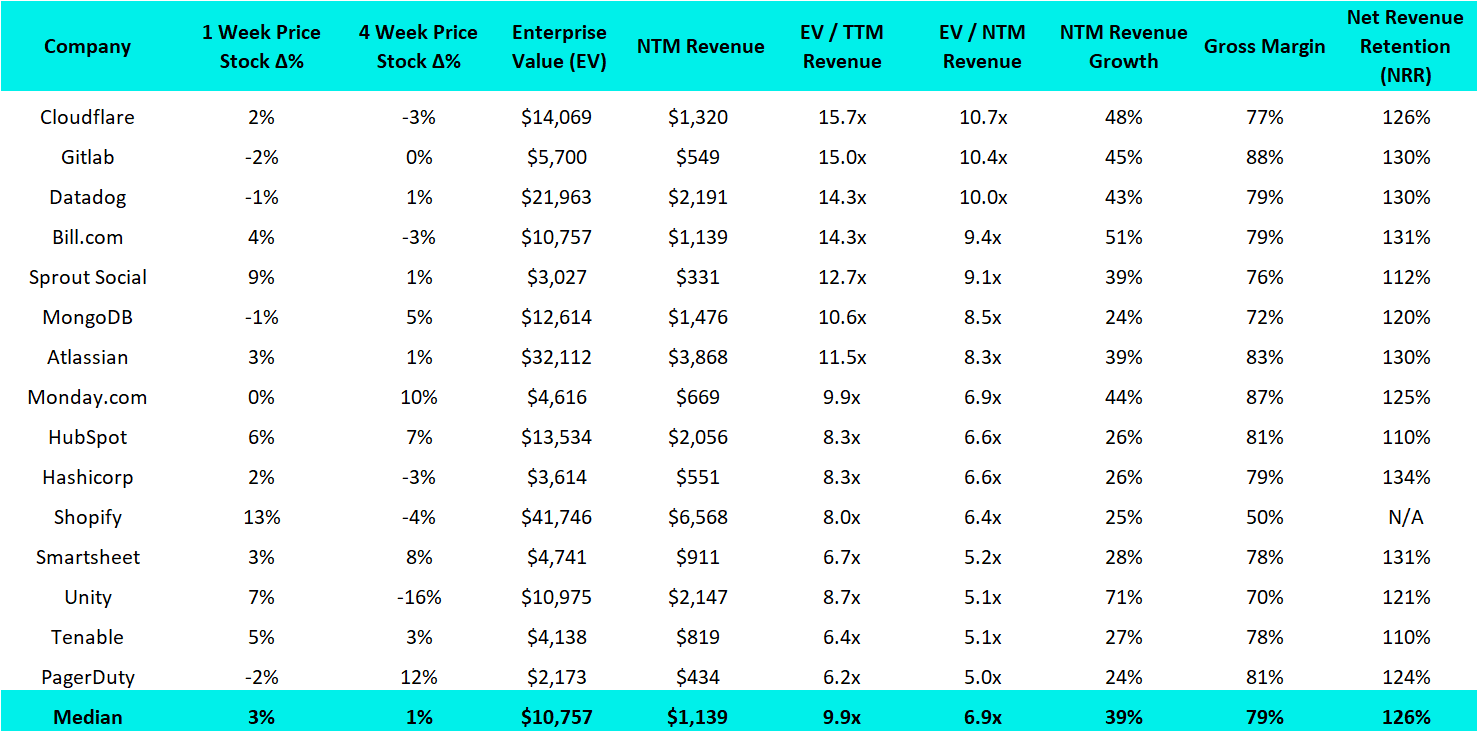
15 Biggest PLG Stock Gainers (1 month):
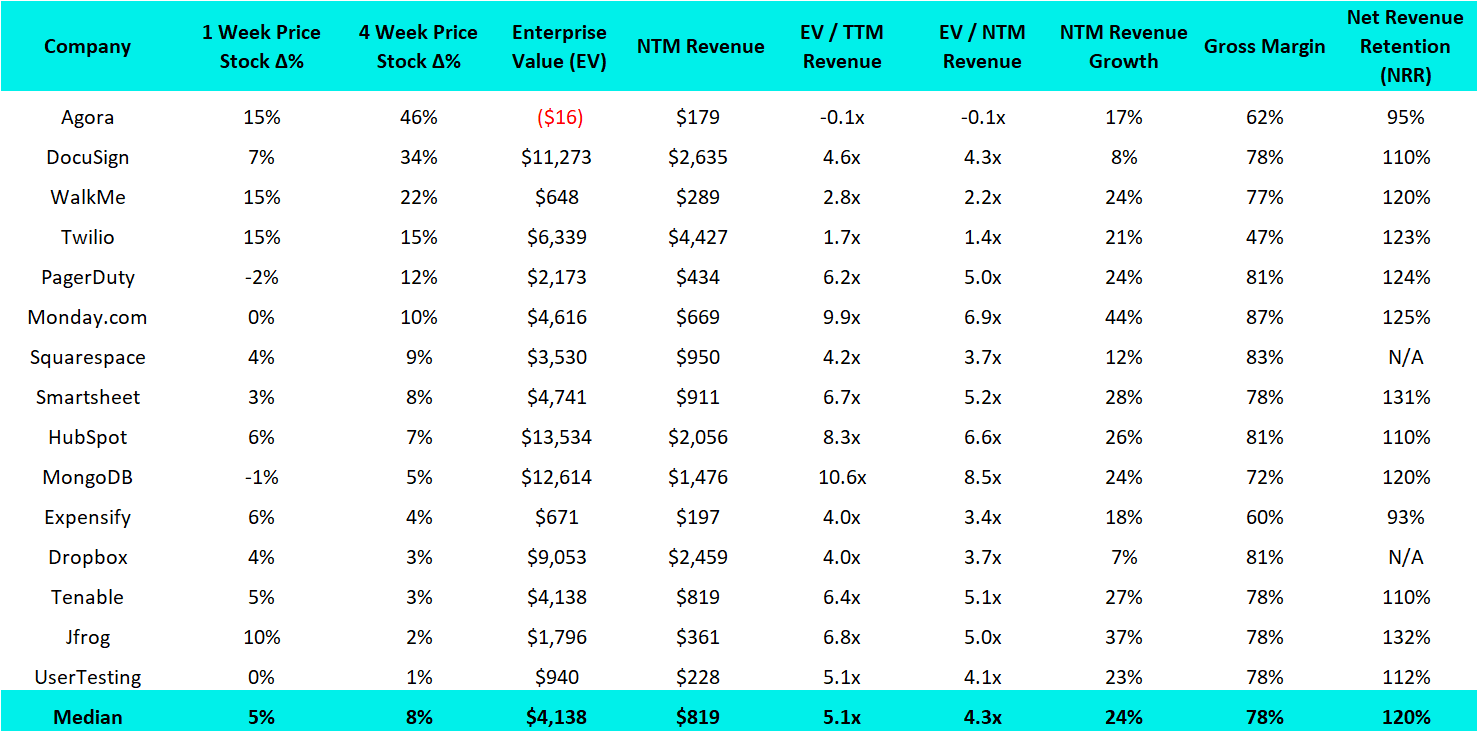
Complete Notorious PLG Dataset (click to zoom):

Note: TTM = Trailing Twelve Months; NTM = Next Twelve Months. Rule of 40 = TTM Revenue Growth % + FCF Margin %. GM-Adjusted CAC Payback = Change in Quarterly Revenue / (Gross Margin % * Prior Quarter Sales & Marketing Expense) * 12. Recent IPOs will have temporary “N/A”s as Wall Street Research has to wait to initiate converge.
Glad to read this post. Folks who are looking to dig deeper into their event data infra can check out this series of guides on the topic: https://databeats.community/p/customer-data-for-product-analytics-series